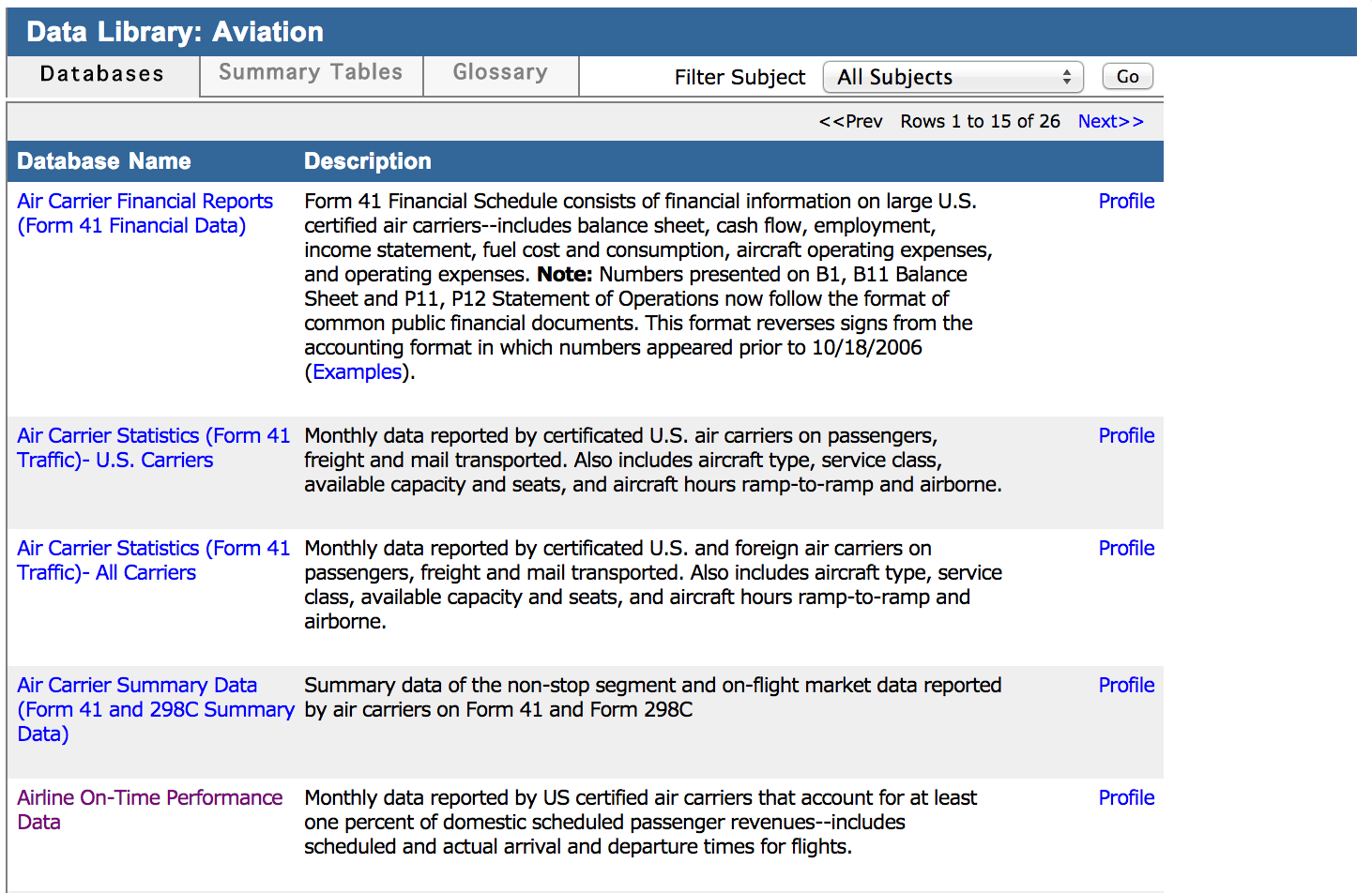
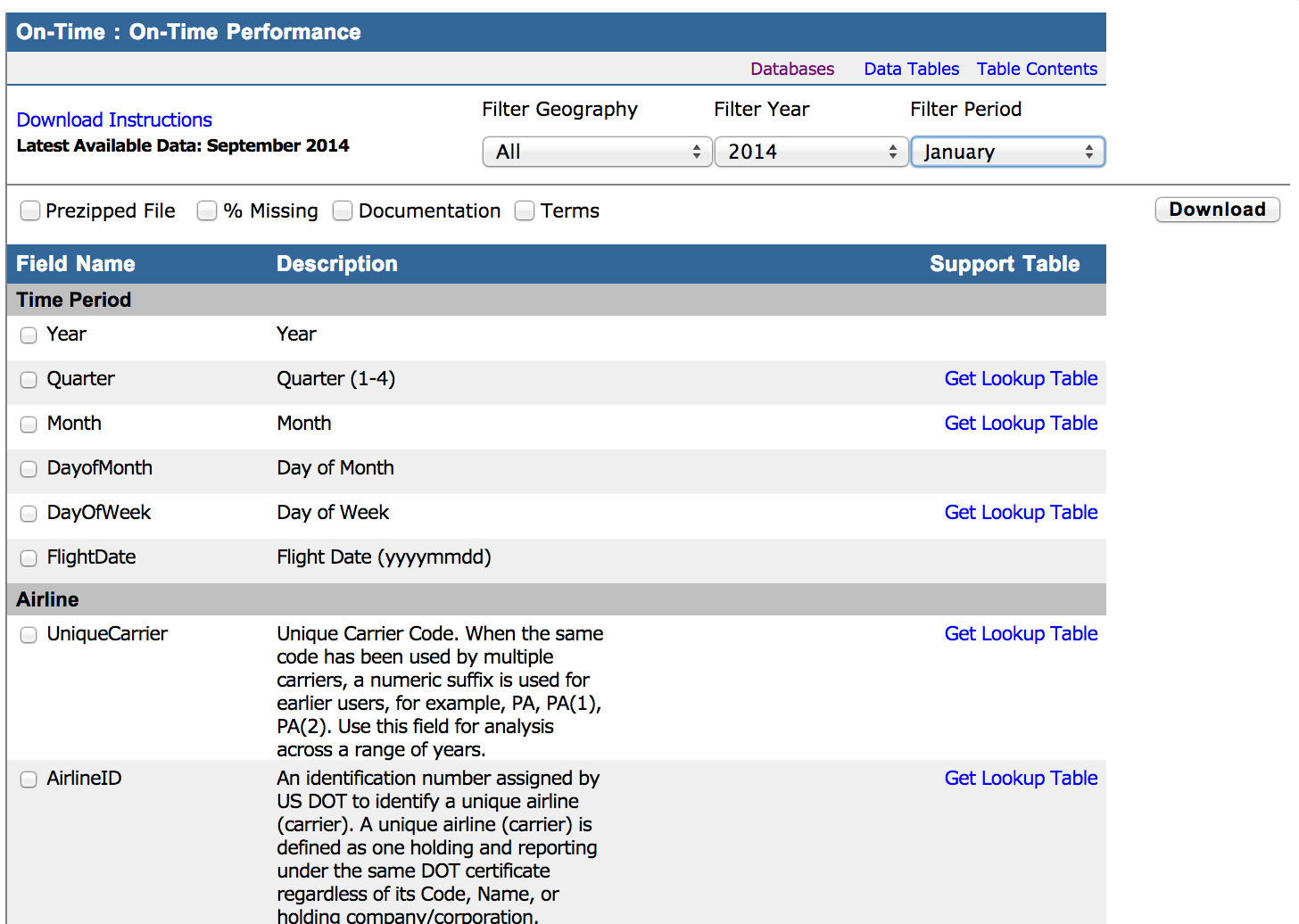
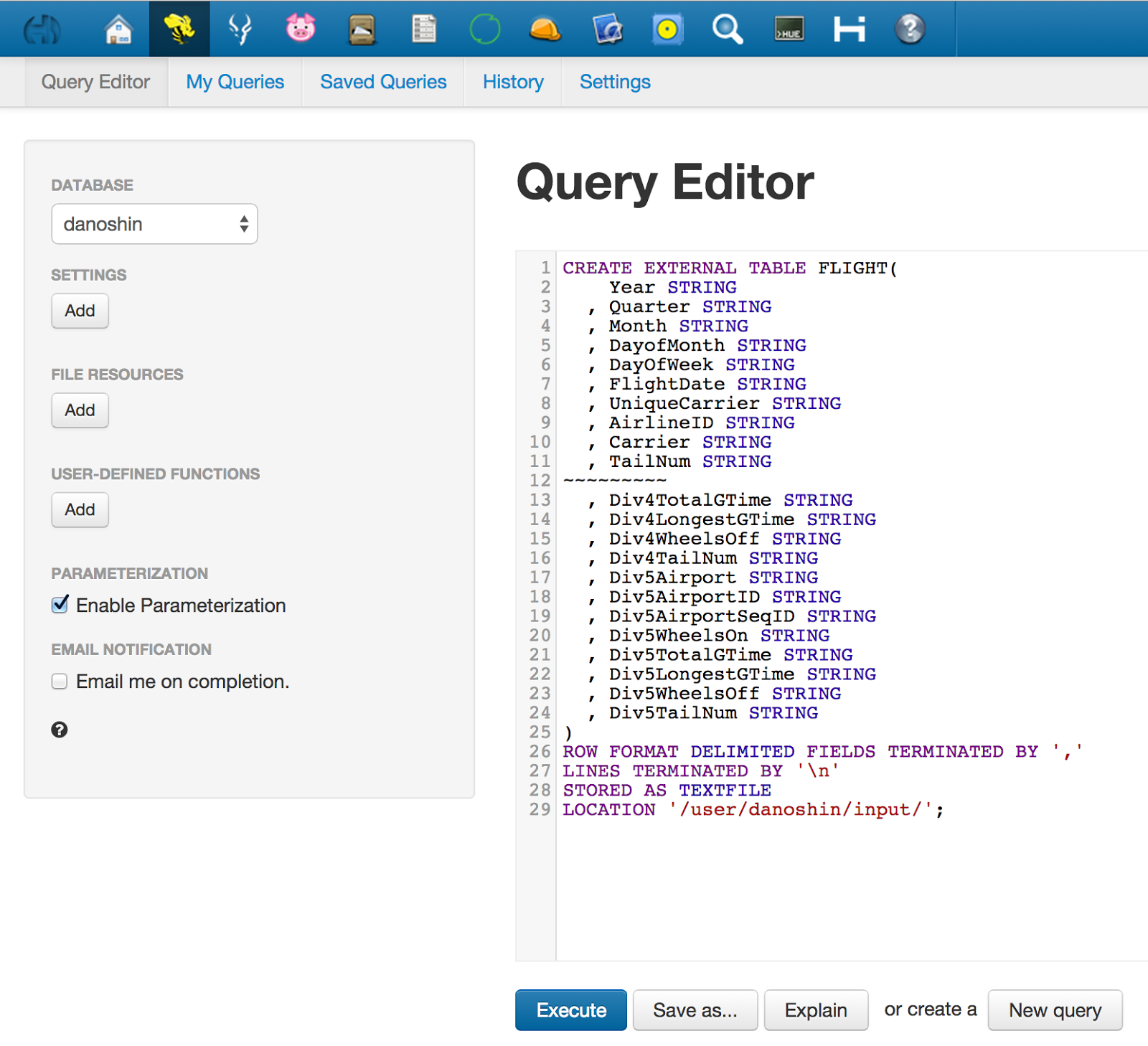
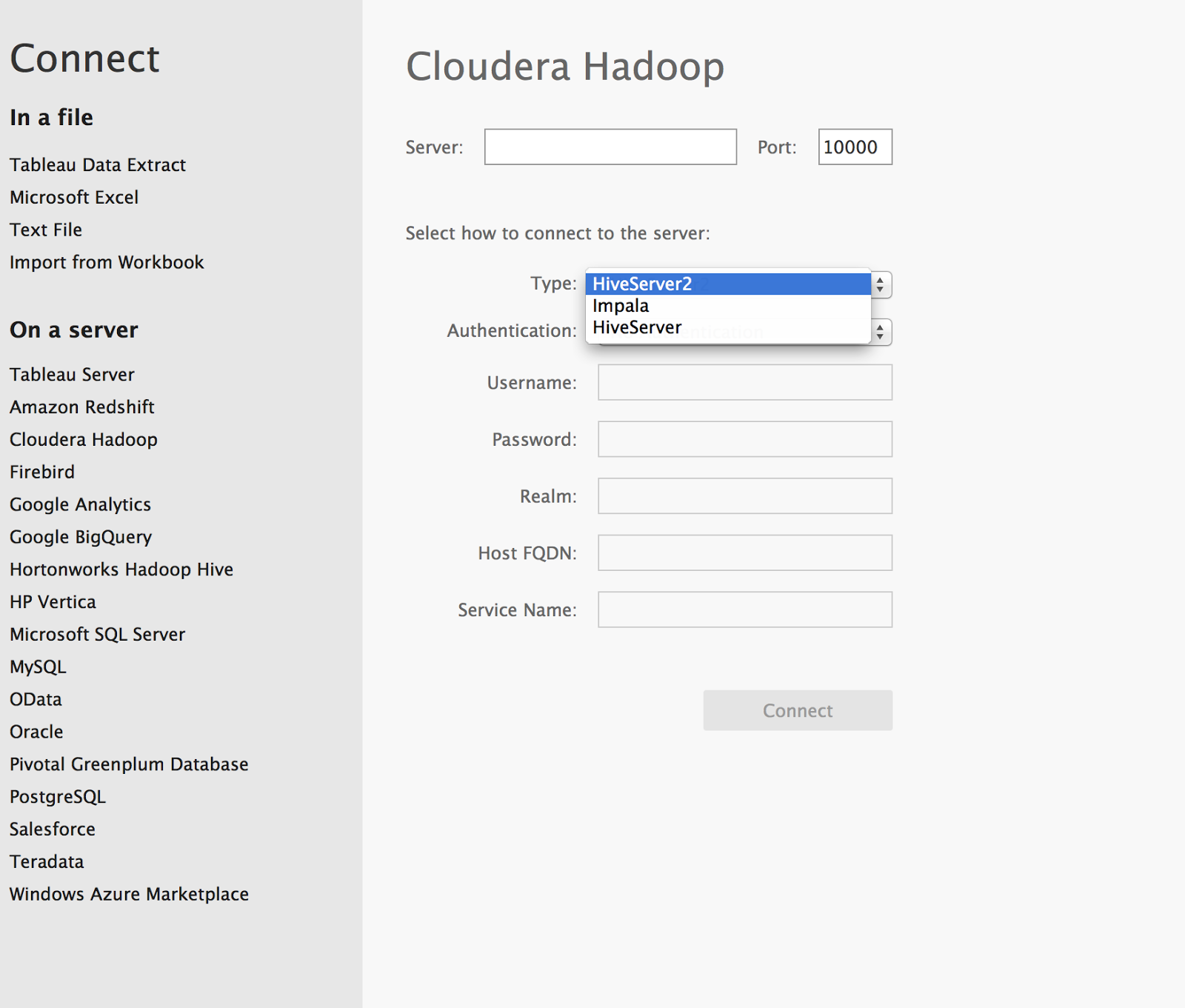
The data warehouse stores the history of the data changes, so you need to sign in to submit only the changed data since the last update in DWH.
Goal:
Solution:
There are several ways to detect changes:
1. Analysis of the column audit or timestamp
The table is added to the system source column contains the date and time of insertion or last update. The value of the column is usually filled with triggers that run automatically when you insert or update. In some cases, in place of the time you can use a monotonically increasing numeric code audit.
cons:
Goal:
- To be sure that the isolation of the changed data
- Provide certain type of change (insert, delete, update)
- Ensure batch downloading changes in DWH
Solution:
There are several ways to detect changes:
1. Analysis of the column audit or timestamp
The table is added to the system source column contains the date and time of insertion or last update. The value of the column is usually filled with triggers that run automatically when you insert or update. In some cases, in place of the time you can use a monotonically increasing numeric code audit.
cons:
- increasing the load on the database system resources and slowing down data modifications because of the trigger;
- if these columns are filled not trigger, then ensure the accuracy of change detection is not possible;
- it is impossible to determine whether the removal;
- problems with the time change to the source server or not synchronized with time DWH (for timestamp);
- storage of digital codes of the last audit exemption for each table (for digital labels).
2. Analysis of tables with the change log
For each tracked table to create a log table that stores all the line after modification, the modification time, and type of modification. Filling a table is done via a trigger to insert, delete, and update the tracked table.
cons:
- increasing the load on the database system resources and slowing down data modifications because of the trigger;
- need to be able to aggregate changes in one line. Since the magazine provides all the changes, the hour might happen inserting rows, updating and subsequent removal;
- the need for periodic cleaning of the magazines;
- problems with the time change to the source server or not synchronized with time DWH;
3. Analysis of log files
The method is to periodically copy the redo log (redo log) database and analysis of these logs in order to highlight the transaction affecting the table you are interested in.
cons:
- magazines not supported by all DBMS;
- need to be able to aggregate changes in one line;
- loss of information about changes in the case of carrying out administrative work.
Often crowded logs that blocks further transactions. When this happens in a commercial transaction system, the reaction responsible DBA is to clean the logs. If you have sorted out all the options, and log analysis was the only appropriate, it is necessary to convince the DBA to create for you a special transaction log.
4. Full comparison
At full comparison holds the full picture of the table on the last day, and compared to each entry with today's version of the search for each change. Gives a guaranteed change detection.
cons:
- the cost of the disk subsystem;
- cost comparison;
- implementation of the algorithm for calculating checksums.