Follow the standard Oracle guides for installing and
configuring OBIEE and the necessary components.
The following has added information on the integration with Teradata.
The Oracle Business
Intelligence Server software uses an initialization file named NQSConfig.INI to
set parameters upon startup. This file includes parameters to customize
behavior based on the requirements of each individual installation. Parameter entries
are read when the Oracle Business Intelligence Server starts up. When you
change an entry when the server is running, you need to shut down and then restart
the server for the change to take effect. When integrating with Teradata, there
are a few parameters in NQSConfig.ini that must be in sync with settings on the
database. The NQSConfig.INI file is
located on the BI server in the subdirectory OracleBI_HOME\server\Config.
·
LOCALE specifies the locale in which data is
returned from the server. This parameter also determines the localized names of
days and months. Below is part of the
chart that shows the settings for the different languages. See the OBIEE installation and configuration
guide for the full list of settings.
·
SORT_ORDER_LOCALE is used to help determine
whether a sort can be done by the database or whether the sort must be done by
the Oracle Business Intelligence Server.
As long as the locale of the database and OBI server match, OBI will
have the database do the sorting. If
they do not match, OBI will do the sorting on the server. If SORT_ORDER_LOCALE is set incorrectly,
wrong answers can result when using multi-database joins, or errors can result
when using the Union, Intersect and Except operators, which all rely on
consistent sorting between the back-end server and the OBI Server.
·
NULL_VALUES_SORT_FIRST specifies if NULL values
sort before other values (ON) or after (OFF). ON and OFF are the only valid
values. The value of NULL_VALUES_SORT_FIRST should be set to ON. If there are other underlying databases that
sort NULL values differently, set the value to correspond to the database that
is used the most in queries.
Here
is a screenshot of a typical NQSConfig.INI file:
Syntax
errors in the NQSConfig.INI file prevent the Oracle Business Intelligence
Server from starting up. The errors are logged to the NQServer.log file,
located in the subdirectory OracleBI_HOME\server\Log.
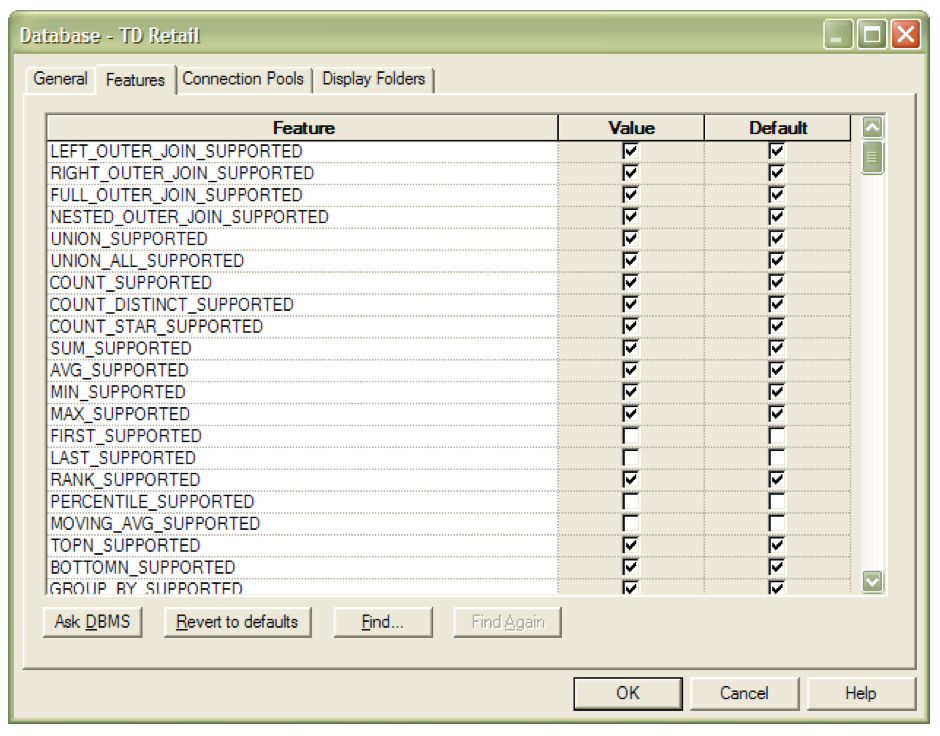
When
you import the schema or specify a database type in the General tab of the
Database dialog box, the Feature table is automatically populated with default
values appropriate for the database type. The database dialog box can be found by
selecting ‘properties’ after right clicking on the highest level folder in the
physical model.
The
feature table holds which SQL features the Analytics Server uses with this data
source. You can tailor the default query features for a data source or
database. For example, if “count distinct” operations don’t always perform well
in your environment you can try turning this function off. This may or may not help performance as OBIEE
will pull back the list and do the count distinct on the server.
Full
outer joins are usually used by OBIEE when joining 2 fact tables via a
dimension. Depending upon the data this
may or may not perform well. Turning
this feature off would force the server to do 1 query against each fact table
and then join the results on the server.
If the result sets are small this could be faster than the full outer
join.
If
you do choose to change the default settings just remember that this is the
global default. What helps one query may
hinder another.
The
drop down list for source database has 3 choices for Teradata. The Teradata choice is actually
mislabeled. This actually has the
settings for Teradata. There are no customizations required for the supported
features settings. If you do choose to
change the default settings just remember that this is the global default. Below is a screen shot of part of the Feature
Table settings.
The connection pool is an
object in the Physical layer that describes access to the data source. It contains
information about the connection between the Analytics Server and that data
source. The Physical layer in the
Administration Tool contains at least one connection pool for each database. When
you create the physical layer by importing a schema for a data source, the
connection pool is created automatically. You can configure multiple connection
pools for a database. Connection pools allow multiple concurrent data source
requests (queries) to share a single database connection, reducing the overhead
of connecting to a database.
During configuration of the connection
pool you should ensure that the ‘call interface’ is set to the correct ODBC
version. This will maximize function
shipping to the Teradata database.
For each connection pool, you must specify the maximum number of concurrent connections
allowed. After this limit is reached, the Oracle BI Server routes all other
connection requests to another allowed connection pool or, if no other allowed connection
pools exist, the connection request waits until a connection becomes available.
Increasing the
allowed number of concurrent connections can potentially increase the load on
the underlying database accessed by the connection pool. Test and consult with
your DBA to make sure the data source can handle the number
of connections specified in the connection pool.
In addition to the potential load and costs associated with
the database resources, the Oracle BI Server allocates shared memory for each
connection upon server startup. This increases Oracle BI Server memory usage
even if there is no activity.
When
determining the number of concurrent connections you must not confuse users
with connections. For instance if you
have on the average 10 users simultaneously hitting a dashboard that has 10
queries embedded then you have 10 users times 10 concurrent connections. On the other hand if your users are only
doing ad-hoc queries then you would only have 10 concurrent connections.
Based
on the number of concurrent queries, the Oracle Business Intelligence Server
Administration Guide has the following advice for maximum connections:
“For deployments with Intelligence Dashboard pages,
consider estimating this value at 10% to 20% of the number of simultaneous
users multiplied by the number of requests on a dashboard. This number may be
adjusted based on usage. The total number of all connections in the repository
should be less than 800. To estimate the maximum connections needed for a
connection pool dedicated to an initialization block, you might use the number
of users concurrently logged on during initialization block execution.”
To
restate a piece of Oracle’s advice – they believe that only 10-20% of
simultaneous users are generating concurrent queries. This obviously will vary by customer and
should only be considered as a starting point for fine tuning. The OBIEE online help states that you should
have different connection pools for:
·
All Authentication and login-specific
initialization blocks such as language, externalized strings, and group
assignments.
·
All initialization blocks that set session
variables.
·
All initialization blocks that set repository
variables. These initialization blocks should always be run using the system
Administrator user login.
Because
each Oracle BI Server has an independent copy of each repository and hence its
own back-end connection pools, back-end databases may experience as many as N*M
connections, where N is the number of active servers in the cluster and M is
the maximum sessions allowed in the connection pool of a single repository.
Therefore, it may be appropriate to reduce the maximum number of sessions
configured in session pools.
Other
experts recommend:
·
Create a separate connection pool for the
execution of aggregate persistence wizard. Remember that you need to give the
schema user owner credentials for this connection pool as the wizard creates
and drops tables
·
If need be create a separate connection pool for
VIPs. You can control who gets to use the connection pool based on the
connection pool permissions.
Lessons from Teradata Professionals
Advise from a Professional Services Consultant:
Concurrency is one of the trickiest questions to address
in my experience. 500 concurrent users will likely not translate to 500
concurrent queries.
The OBIEE interface design will determine how many queries
will be submitted concurrent with a single user accessing the page. If the
queries are sub-optimal even a couple of them may cause issues. When faced with such questions from the customer
we have tried to highlight that it is query performance more than the
concurrent users that will matter in the long run. If all the queries are
well-tuned and finish in a few seconds, then it is not likely that one will see
too many queries running concurrently on the system.
[At a large customer I] found
that an OBIEE application having more than 500 users never had more than 10
users logged in simultaneously and even fewer queries running concurrently.
Advise from a Professional Services Consultant:
I had 8000 marketing and sales users on a system and they
were targeting 50 concurrent users. In reality, we saw 12 max concurrent
QUERIES with 1.5 to 2 being the normal load.
Use multiple BI users (connection pools) to access TD to
spread the resources as we allocate spool, CPU, etc by user. Use the OBIEE
cache facilities so as not to re-execute the queries for another user trying to
get same info.
Define concurrency well before the test. Are they talking
about 500 users logged on and doing normal work plus studying charts, getting
coffee, etc, or 500 concurrent queries? They are vastly different…
Connection pools work
in conjunction with the “connection pooling timeout” setting. The timeout specifies
the amount of time, in minutes, that a connection to the data source will
remain open after a request completes. During this time, new requests use this
connection rather than opening a new one (up to the number specified for the
maximum connections). The time is reset after each completed connection
request. If you set
the timeout to 0, connection pooling is disabled; that is, each connection to
the data source terminates
immediately when the request completes. Any new connections either use another
connection pool or open a new connection.
The typical BI server will
have one “connection pool” login to Teradata.
However, when different end-users need to be given different priorities
on Teradata the single connection pool connection may not suffice. In this case, multiple connection pools could
be configured in the OBIEE physical layer.
Each connection pool user name can then be assigned a different Teradata
account. Multiple connection pools allow
for multiple Teradata logins and therefore allow each login to each have its
own priority/security assigned.
OBIEE can be set up for Teradata Query Banding (QB). This should be considered a work-around until
full query banding functionality is built into OBIEE. To
enable QB, the appropriate SQL is added as a connection script that is executed
before each query. This is found in the
connection pool properties for the Teradata database. On the “connection scripts” tab there is an
“execute before query” section. By
clicking on the “new” button the following sql can be added:
set query_band = 'ApplicationName=OBIEE;ClientUser=valueof(NQ_SESSION.USER);'
for session;
The
metadata for the server needs to be reloaded via the Answers link or by
restarting the OBIEE server. The DBQL
tables will then reflect the OBIEE user executing the query. In this example the OBIEE server logs into TD
with the user called sampledata. Each
OBIEE user is then identified with the query that they ran via the query
band. There are 2 users that ran OBIEE
answer reports: demo and Administrator.
The query banding must be set for the session. Setting for transaction won’t work due to the
way that OBIEE sends the sql to Teradata.
Other arguments may be added to the query band.
For more information on Query Banding in Teradata see the
Teradata Orange Books “Using Query Banding in Teradata Database 12.0”, “Using
Query Banding in
Teradata Database 13.0” and “Reserved QueryBand Names”.
If you have OBIEE
configured against a warehouse and you forklift the warehouse to a different
platform, Oracle fully supports changing the data source from the original
platform to the new platform. No other
OBIEE configuration changes should be necessary. If only forklifting a database was so easy! No data type changes to worry about, no
population scripts …
OBIEE has the capability to write data to the Teradata
database. This could be used by users
who want to do planning or budgeting on a small scale. They could use OBIEE
both as a reporting tool and also for entering sales quotas or budgets
etc. In Answers write-back is configured on a report by report basis. The columns that are available for write-back
appear in a box format for the end user.
There are multiple steps to configure write-back:
- The privilege
must be explicitly granted to each user from Answers (even administrators). The navigation path is: Answers >
Settings > Administration > Manage Privileges > Write Back
- The
column(s) that are to be written back to the database must then be
identified in each Answers report. Column Properties > Column Format tab
> Value Interaction > Type > Write Back
- Create
a XML Template that holds the sql to execute for the write-back in the
{ORACLEBI}/web/msgdb/customMessages folder. You must include both an <insert>
and an <update> element in the template. If you do not want to
include SQL commands for one of the elements then you must insert a blank
space between the unused opening and closing tags.
- Set
the write-back properties for the report.
The Write-back property button is only visible in Answers “table”
view.
Tips/Traps:
- Each
connection pool name must be
unique in the entire .rpd file.
- Make
the table that write-back is enabled for “not cacheable”. This is an attribute on the physical
property box for the table under the “general” tab.











