Nowadays we have to work with really big volume of data. Unfortunately classical relation database are weak and can't handle this challenge. Of course, if we have 1 Mln $ we can buy MPP database such as Teradata, Vertica, Exadata or Netezza. But most organization starting look at Hadoop, especially on commercial distributives such as Apache or Cloudera.
It is not a secret that it is not easy to work with Hadoop, and you have to hire expensive geeks, who can work with this staff.
Anyway, lets imagine, that we have Cluster of Hadoop, in my case it is Cloudera Hadoop. And we, as BI professionals, need to do analytics on top of Hadoop, but unfortunately, we don't know Java in order to write MapReduce Jobs, and we start to look at Hive or Impala in order to work with usual SQL, of course with restrictions.
The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
Impala is a fully integrated, state-of-the-art analytic database architected specifically to leverage the flexibility and scalability strengths of Hadoop - combining the familiar SQL support and multi-user performance of a traditional analytic database with the rock-solid foundation of open source Apache Hadoop and the production-grade security and management extensions of Cloudera Enterprise.
But just SQL isn't enough for powerful analytics, we want Charts, drag and drop, slice and dice:)
Specially for us, leading BI platforms such as Tableau, Microstrategy, Pentaho and other make possible to connect Hadoop via Hive/Impala ODBC driver.
In my case I will demonstrate how you can establish connection between Hadoop and Tableau.
Let's start.
Get data
First of all, we need data. The best sample data and the most popular data in the Internet is Flight data.
The Bureau of Transportation Statistics has a web site dedicated to TranStats, which is the Intermodal Transportation Database. This database contains information that is regularly updated on aviation, maritime, highway, rail, and other modes of transportation. As described earlier, we will focus only on the Airline On-Time Performance data, which is
made available as a simple table that contains departure and arrival data for all the scheduled nonstop flights that occur exclusively within the United States of America. The data is reported on a monthly basis by U.S. certified carriers that account for at least one percent of the domestic scheduled passenger revenues. The flight data and a description
are available at the following URL: http://www.transtats.bts.gov/

Selecting the Aviation link will take you to a page that presents a list of aviation related databases. On this list, select the Airline On-Time Performance Data by clicking on the name of the database. This will take you to the next page, which shows more detailed information about the database we are interested in. Here you will click on the download link as shown in Figure:
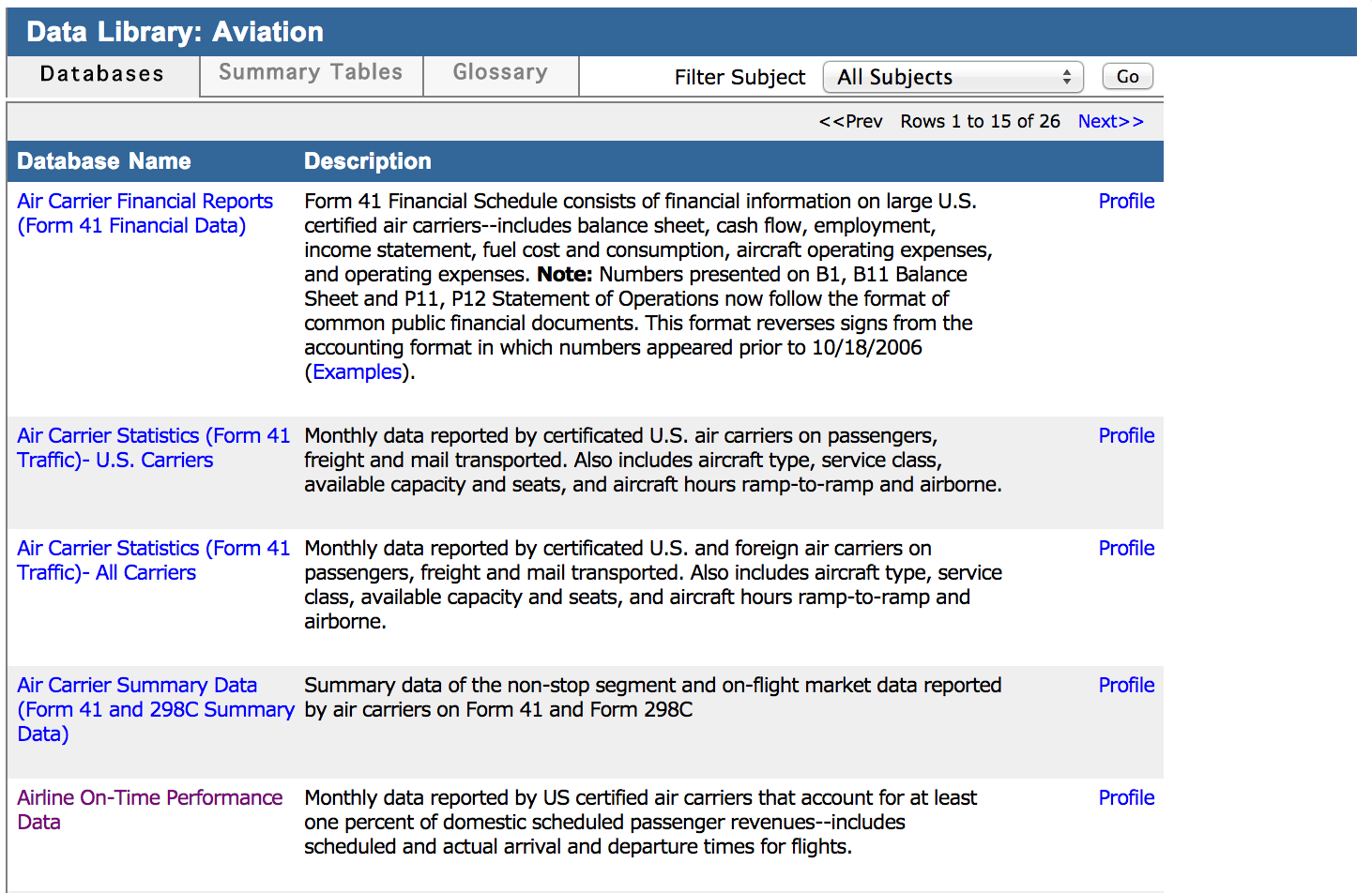
Here you can download data for the specific month in CSV format:
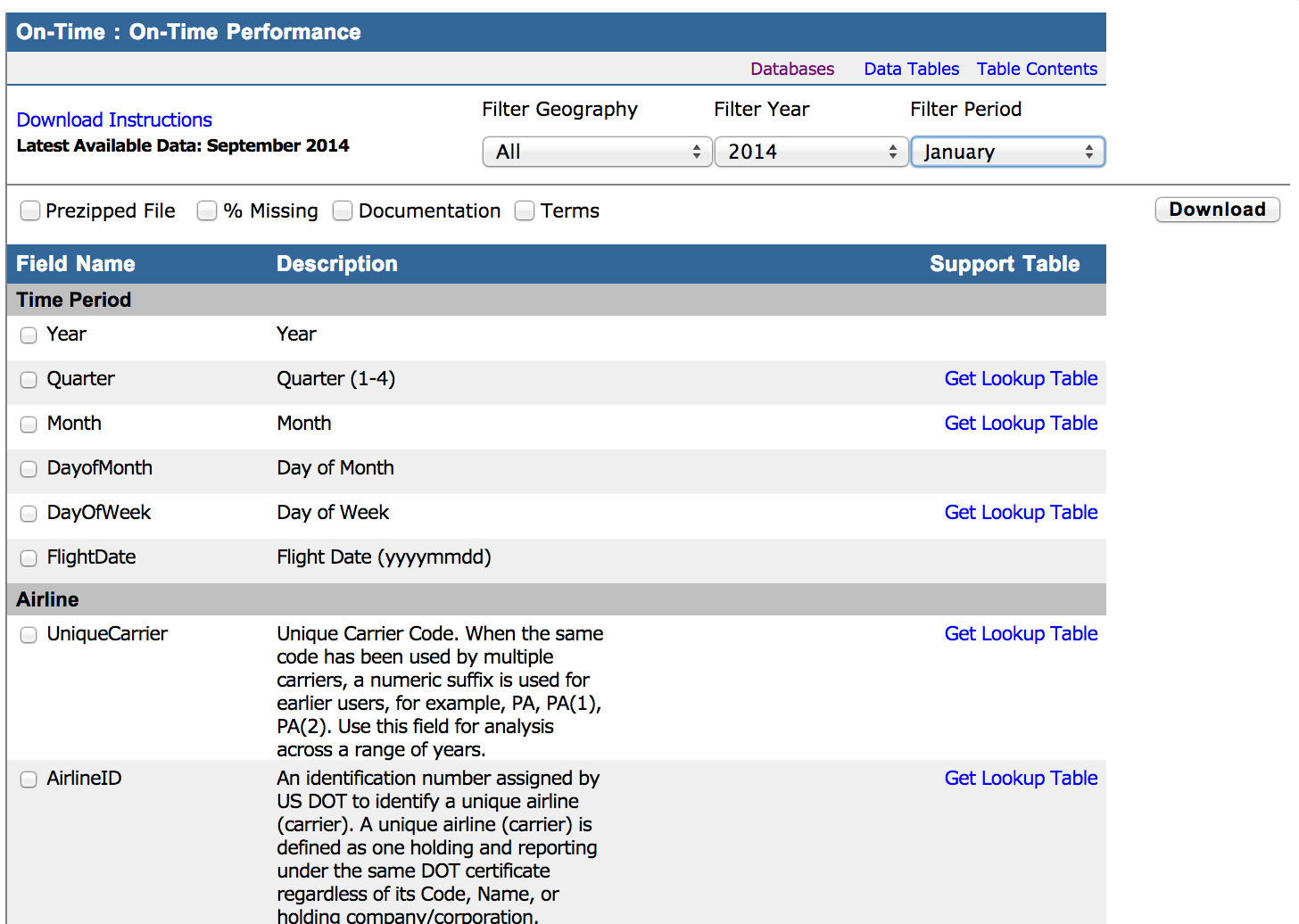



Get data via Tableau
Now we can open Tableau and choose connection to Cloudera hive.
By default it has port 10000, be aware, you need to check, that service for connection to hadoop has to work.
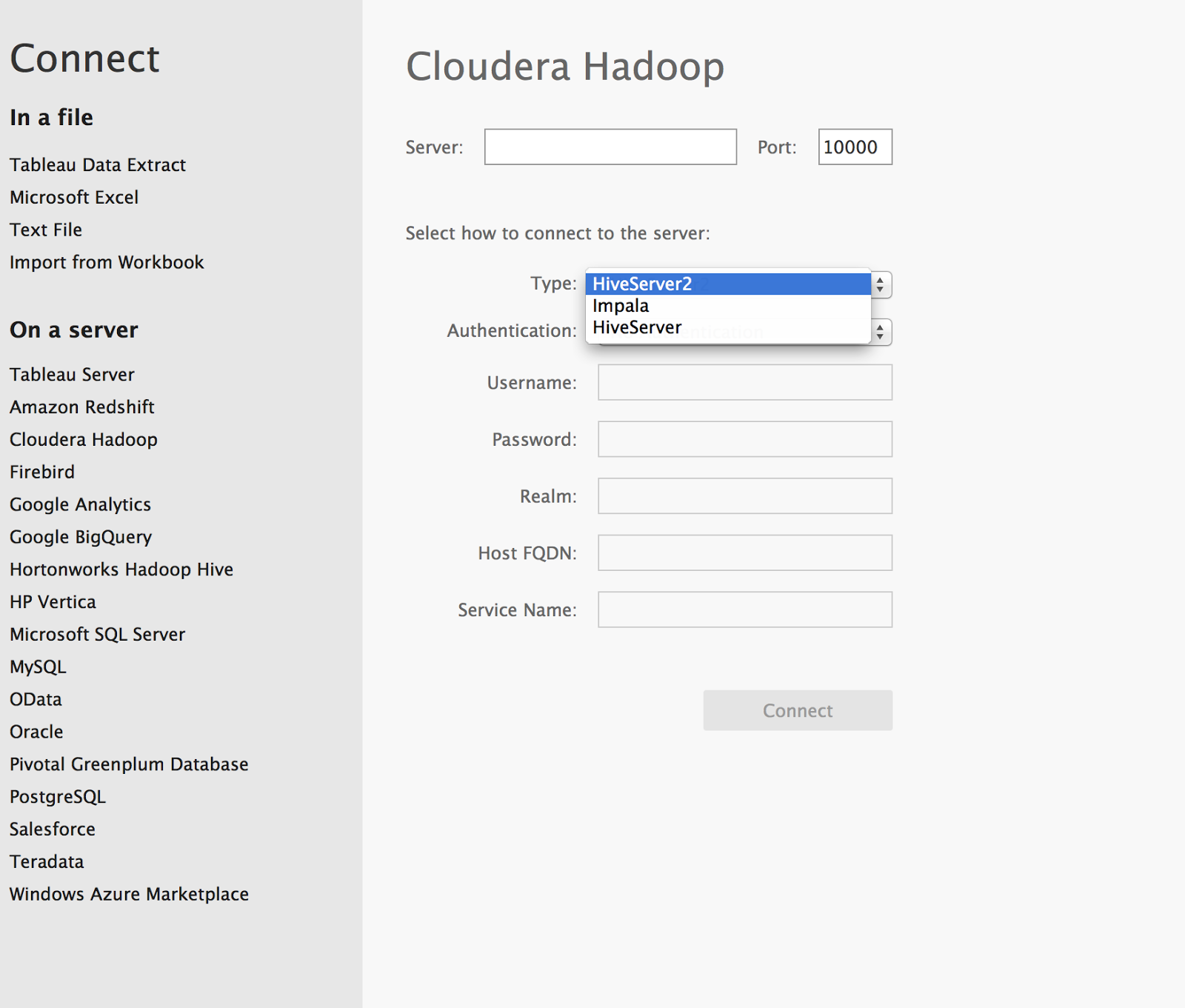
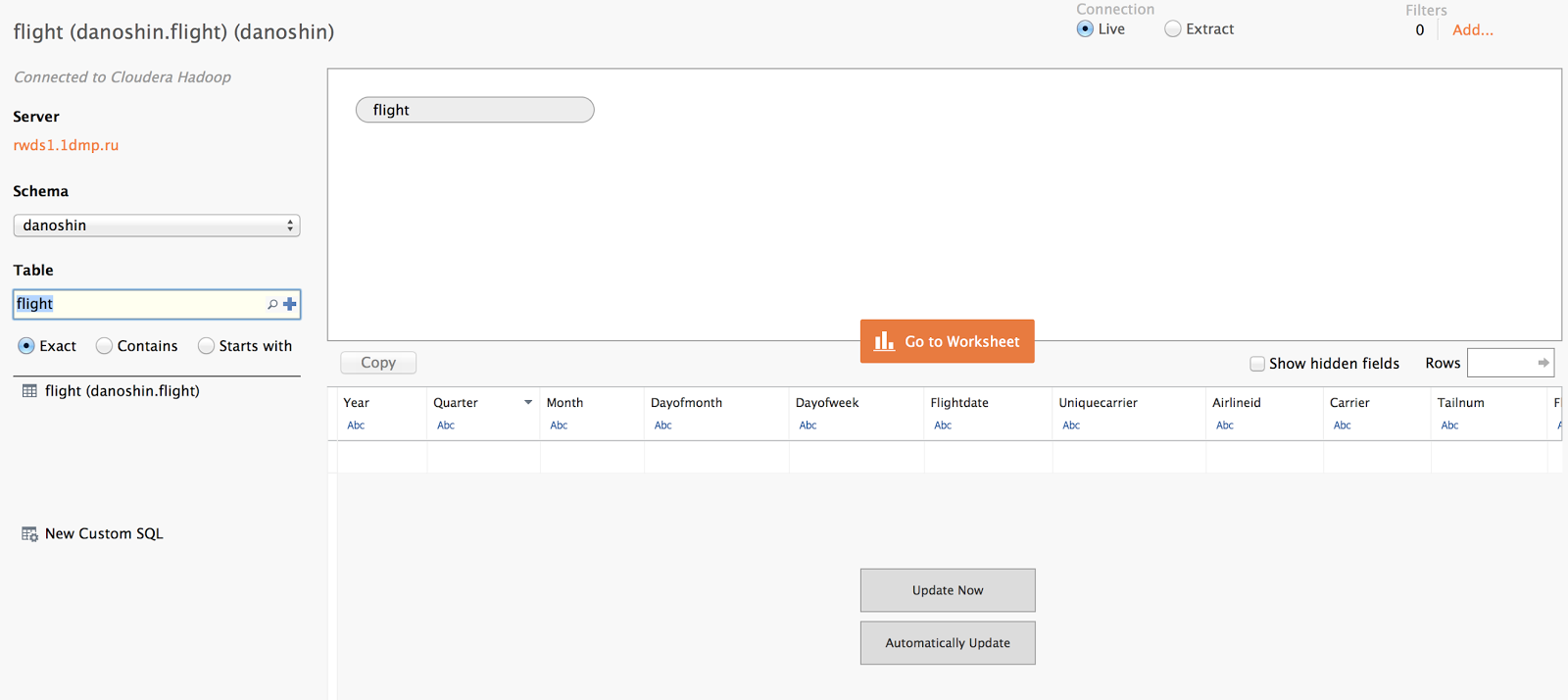
Finally, you are almost there, just push "Go to worksheet"

It is not a secret that it is not easy to work with Hadoop, and you have to hire expensive geeks, who can work with this staff.
Anyway, lets imagine, that we have Cluster of Hadoop, in my case it is Cloudera Hadoop. And we, as BI professionals, need to do analytics on top of Hadoop, but unfortunately, we don't know Java in order to write MapReduce Jobs, and we start to look at Hive or Impala in order to work with usual SQL, of course with restrictions.
The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
Impala is a fully integrated, state-of-the-art analytic database architected specifically to leverage the flexibility and scalability strengths of Hadoop - combining the familiar SQL support and multi-user performance of a traditional analytic database with the rock-solid foundation of open source Apache Hadoop and the production-grade security and management extensions of Cloudera Enterprise.
But just SQL isn't enough for powerful analytics, we want Charts, drag and drop, slice and dice:)
Specially for us, leading BI platforms such as Tableau, Microstrategy, Pentaho and other make possible to connect Hadoop via Hive/Impala ODBC driver.
In my case I will demonstrate how you can establish connection between Hadoop and Tableau.
Let's start.
Get data
First of all, we need data. The best sample data and the most popular data in the Internet is Flight data.
The Bureau of Transportation Statistics has a web site dedicated to TranStats, which is the Intermodal Transportation Database. This database contains information that is regularly updated on aviation, maritime, highway, rail, and other modes of transportation. As described earlier, we will focus only on the Airline On-Time Performance data, which is
made available as a simple table that contains departure and arrival data for all the scheduled nonstop flights that occur exclusively within the United States of America. The data is reported on a monthly basis by U.S. certified carriers that account for at least one percent of the domestic scheduled passenger revenues. The flight data and a description
are available at the following URL: http://www.transtats.bts.gov/
In the left bar find Data Finder->By Mode->Aviation
Here you can download data for the specific month in CSV format:
But it is a long road to download all data since 1989:)
You can use command wget or curl and download all files via shell script. There is an example on my mac:
wget "http://www.transtats.bts.gov/Download/On_Time_Performance_1986_11.zip"
PS 11/86 - my birth year month:)
Small tip: you can use parameters and for in order to cut the road.
Finally, we get data.
Upload data
Now we have to upload data into Hadoop.
I use HUE.
Hue is a set of web applications that enable you to interact with a CDH cluster. Hue applications let you browse HDFS, manage a Hive metastore, and run Hive and Cloudera Impala queries, HBase and Sqoop commands, Pig scripts, MapReduce jobs, and Oozie workflows.
Hue Architecture
Hue applications run in a Web browser and require no client installation.
The following figure illustrates how Hue works. Hue Server is a "container" web application that sits in between CDH and the browser. It hosts all the Hue web applications and communicates with CDH components.
Connect to HUE and go to file browser:
Push "Upload" and select or CSV file.
Create database
Now we can create database "danoshin" via Metastore Manager:
Create table
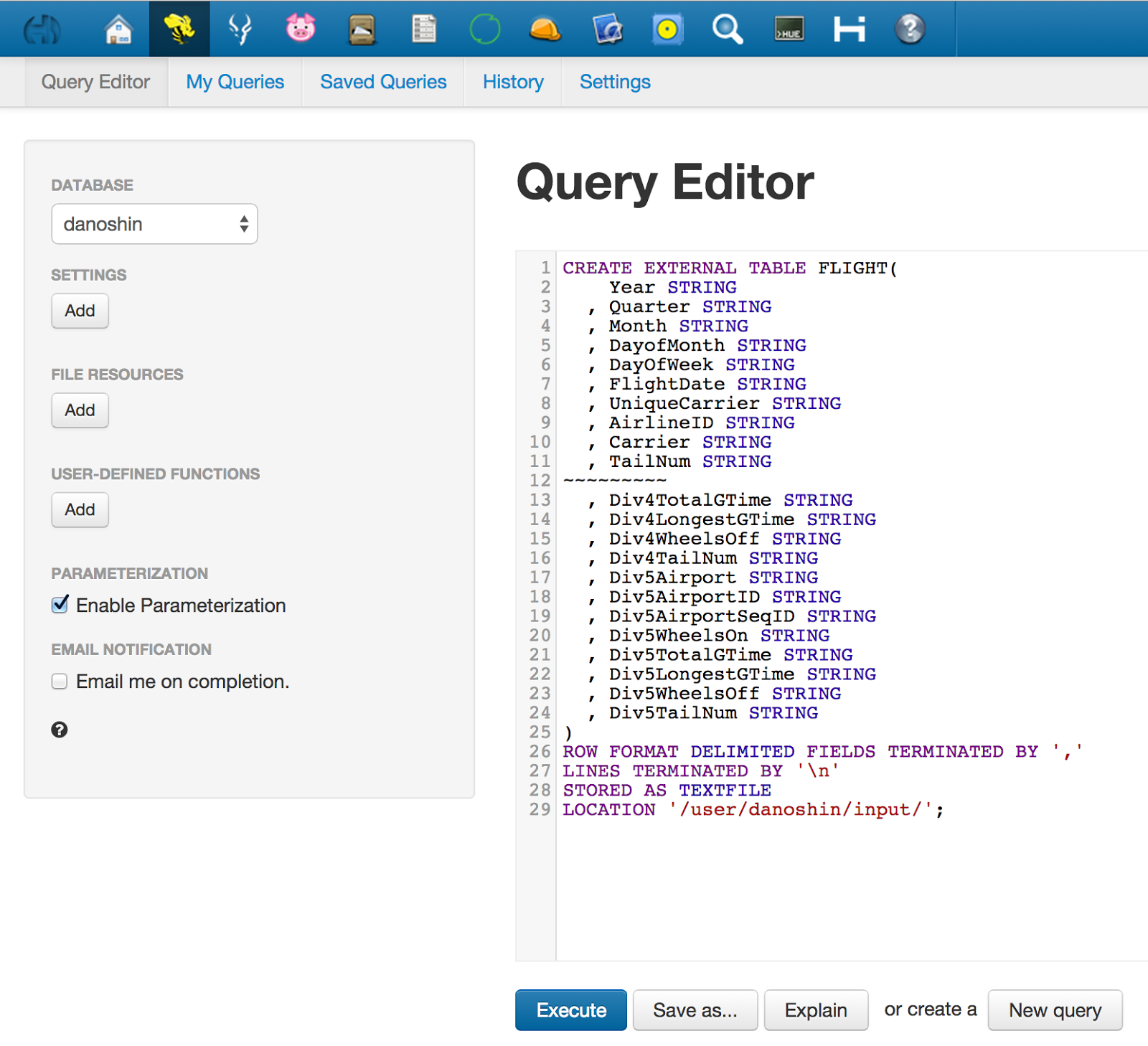
We can create new table "flight" via Hive in our database
(with ~ I cut some fields, but you need all fields):
Parameters:
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' - specify delimiter;
LINES TERMINATED BY '\n' - end of row;
STORED AS TEXTFILE - type of file;
LOCATION '/user/danoshin/input/' - location in HDFS;
In case if file has header, we need delete it, you can do it Hive query:
INSERT OVERWRITE TABLE FLIGHT
SELECT * FROM FLIGHT WHERE YEAR <> '"Year"'
Now we can open Tableau and choose connection to Cloudera hive.
By default it has port 10000, be aware, you need to check, that service for connection to hadoop has to work.
If you are wondered about Hive and Hive2, there are some points for you:
- HiveServer2 Thrift API spec
- JDBC/ODBC HiveServer2 drivers
- Concurrent Thrift clients with memory leak fixes and session/config info
- Kerberos authentication
- Authorization to improve GRANT/ROLE and code injection vectors
When you type credentials, you can find your database and table:
Finally, you are almost there, just push "Go to worksheet"
There is small chart, and we can figure out, that WN airlines the most popular in that time:)
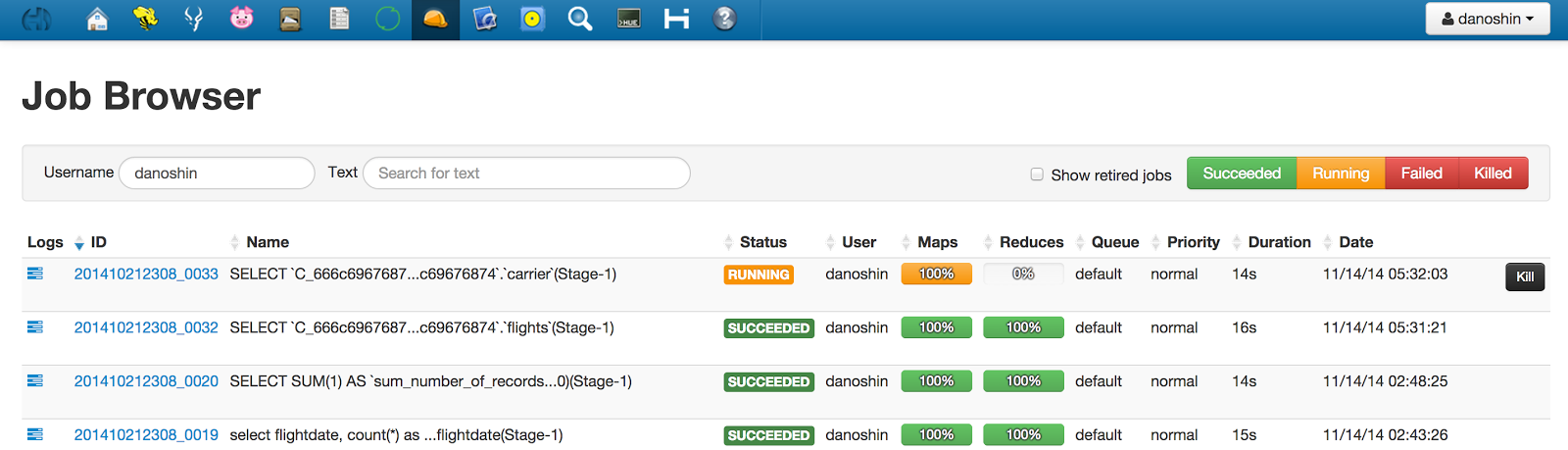
In addition, you can monitoring job execution in Job Manager: